Optimising Cloud Storage in AWS and finding the Secret Cost Report

Cloud Storage using AWS
Most businesses operating in AWS will typically end up being heavy users of their storage service S3. S3 (alongside EC2) is one of the most successful infrastructure as a service (IaaS) offerings of AWS. The ability to scale up & down storage as needed and with all the capabilities required of modern businesses is an important enabler for growth. Those key capabilities that are needed include:
Durability, Performance and Availability: The ability to easily control redundancy and performance capabilities via configuration is extremely powerful.
Security and compliance: Being able to control where your data is stored, who can access it, whether it can be modified, and if and how it is encrypted.
Models of Use
The most common uses of cloud storage are related to:
- Application Management
- Datalakes (for analytic and data processing / warehousing pipelines)
- Backup and Disaster Recovery (DR)
- Audit, Compliance and Archive
Each of these will has different configurations that will be optimised for use.
Operational Challenges
The challenge for the infrastructure manager is that data is easy to generate or receive, but much harder to delete. Past business orthodoxy is that data was the new oil, and that holding data would enable the success that oil created in its heyday. This belief in the opportunity enabled by data, and the hesitancy faced by anyone asked if an item can be removed permanently has resulted in ever increasing data foot prints. But more recent thinking, in the light of many serious and highly damaging data breaches is that data is more like uranium than oil. Note: I believe it’s mandatory at every conference (no matter what the topic is) for someone to mention this. The metaphor being that data while powerful and with the ability to enable a business to succeed, can also be dangerous if mishandled or allowed to escape from control.
In theory building a system that can self-manage through automated retention rules can avoid a lot of this pain. In practice (at least where humans are involved) it can be hard to achieve universally. This ever-expanding data footprint will likely proceed unnoticed until the cost of it forces attention to be applied. It’s when you start trying to manage the cost of S3 that you really start diving into the configuration options that are available.
Management Tools - Storage Lens
The recommended tool for managing S3 in AWS is Storage Lens. It is an analytics service that is helpful in many ways but particularly for:
- Usage Monitoring: The number of objects, bucket sizes, and growth trends.
- Activity Insights : Request pattern and access frequency reporting
- Cost Optimisation: Helps identify unused or rarely accessed data so you can move it to lower-cost storage classes
- Security & Compliance Monitoring: Detects potential security risks such as publicly accessible buckets
- Multi-Account Visibility : Allows centralised reporting across multi-account setups
But, accessing many of these features in a useful way requires enabling the premium (paid) version of Storage Lens which at scale can be expensive.
Managing Usage and Costs
The cost explorer will give the basics quite easily and allow you to present cost and filter/or group by all the usual parameters you would want.
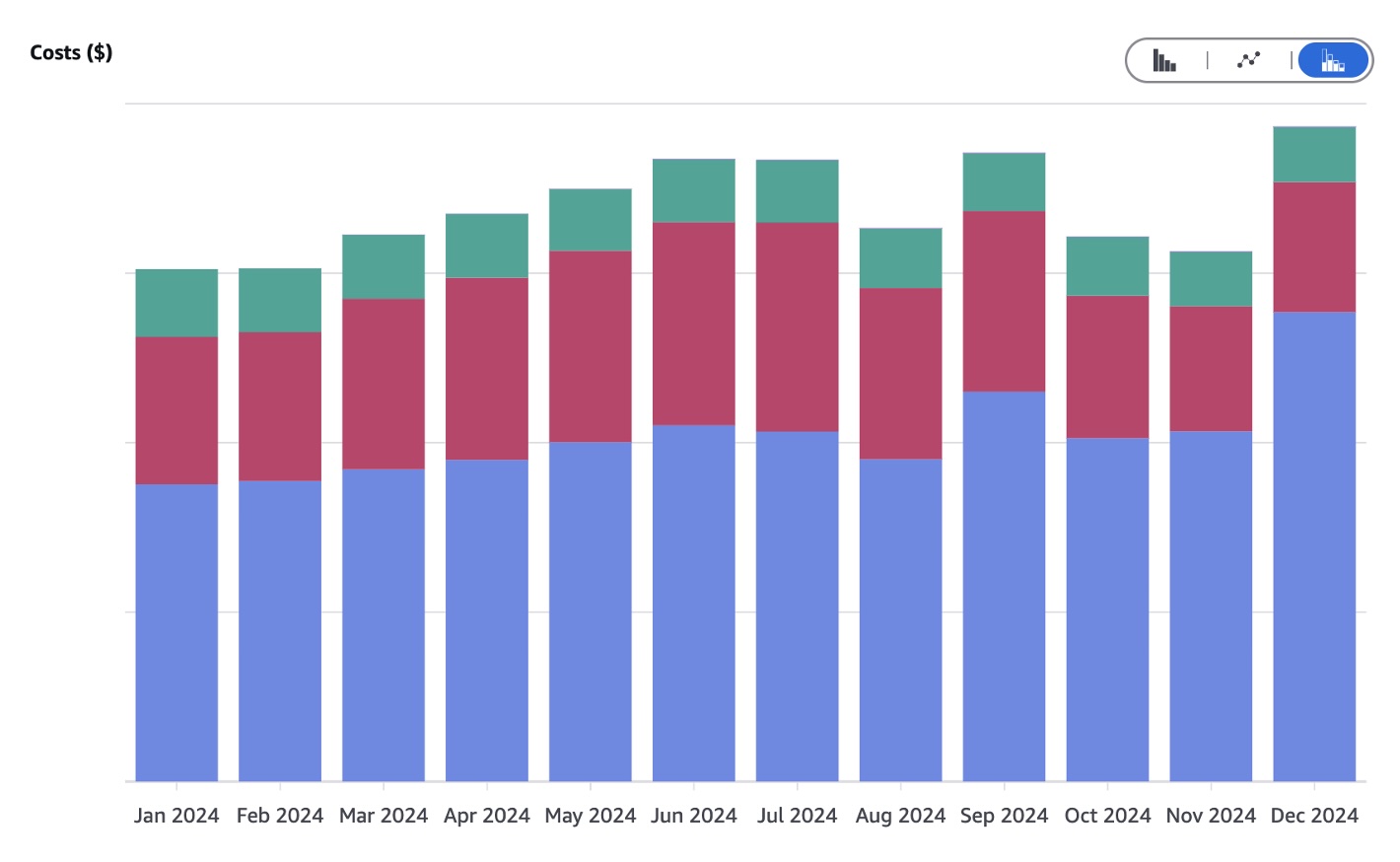
The issue soon arises that cost per GB varies depending on the storage class you are using. And further complicating that picture is that file count matters and many smaller files can end up costing much more than fewer larger files of the same overall size.
It’s also natural to focus on the footprint (size) of cloud data storage, but a key element of cost is network transfers. These could be within AWS’s networks or out of their networks (but not into their cloud which they will happily do for free). Transfer costs and penalties associated with file count are the 2 hidden cost pain points of cloud storage.
Activating the secret Storage usage report
The cost explorer claims to present cost and usage but by default it actually only shows cost. To access the usage panel you need to do a not-obvious filtering step of navigating to the Usage type filtering menu. From there you need to search for “timedstorage” and then enable all options (there were 28 when I last ran this but presumably that will change over time and will need be reviewed).

After you do this and without any obvious reason why, a new panel will accompany the cost one which is actually usage.
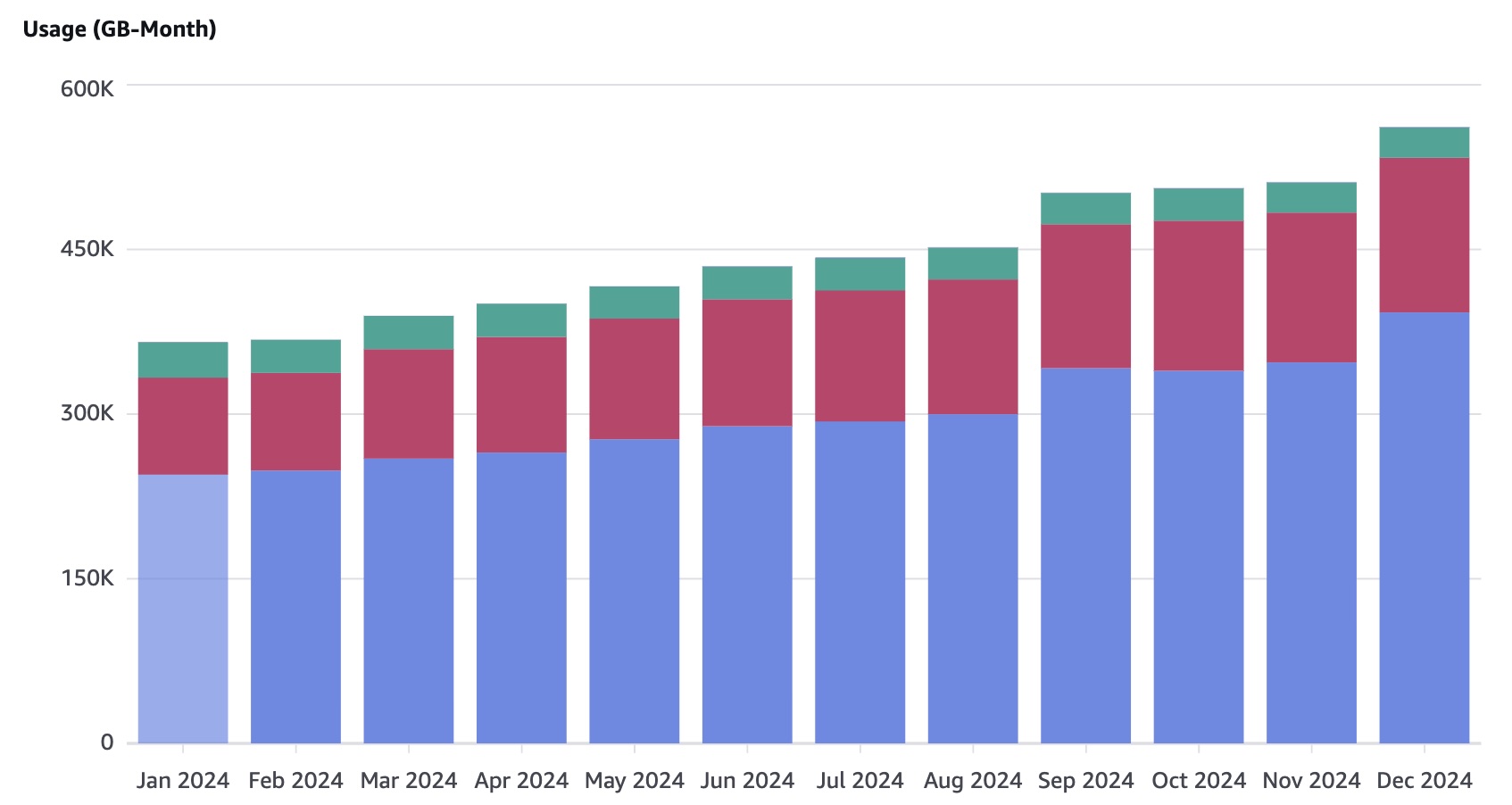
By combining the two views of usage and cost, along with the powerful filtering and grouping capabilities of cost explorer you can get a very clear picture of what is happening with the data storage.
Having gained a deep understanding of usage patterns, what next?
The key goal will always be to delete what is not required. But presuming that process is taken as far as practical, the next step for managing cost is to think about the storage class used for each case. Where the requirement for access/retrieval is not immediate there are options for lower cost.
| Storage Class | Access Frequency | Cost | Retrieval Time | Use Case |
|---|---|---|---|---|
| S3 Standard | Frequent | High | Instant | Websites, apps |
| Intelligent-Tiering | Varies | Moderate | Instant | Data lakes, ML |
| Standard-IA | Infrequent | Lower | Instant | Backups |
| One Zone-IA | Infrequent | Lower | Instant | Secondary backups |
| Glacier Instant Retrieval | Rare | Low | Milliseconds | Compliance data |
| Glacier Flexible Retrieval | Rare | Lowest | 1 min – 12 hrs | Long-term storage |
| Glacier Deep Archive | Very Rare | Cheapest | 12 – 48 hrs | Regulatory archives |
| S3 Outposts | Frequent | High | Instant | Hybrid cloud |
| S3 Express One Zone | Frequent | High | Instant | AI/ML, analytics |
AWS S3 Intelligent Tiering
Where there is:
- an ongoing requirement for (potential) instant access
- and it’s not possible to say whether the data can be deleted or not
then intelligent tiering can be an appealing model for dynamic storage-class control that is managed by AWS. In this model AWS tracks the access pattern for objects and will over time progress that object through cheaper classes of storage on the basis that this lack of access will continue. We can eventually get the benefits of cheaper storage classes without having to make the decision as to what that class should be.
The data starts in the ‘Frequent Access’ (FA) tier. After 30 days it graduates to ‘Infrequent Access’ (IA). At this level the reduction in cost is around 40%. If there continues to be no interaction with the data, it then graduates to ‘Archive Access’ (AA). At AA level the cost reduction is around 60% from FA.
Essentially it’s a bet that over a basket of objects most will not be frequently accessed and therefore justify a cheaper cost. From the cost explorer and when grouping by usage type, you can then tell a story of what is happening with the data which is quite powerful to understand the relationship between access patterns, sizing and cost such as the following:
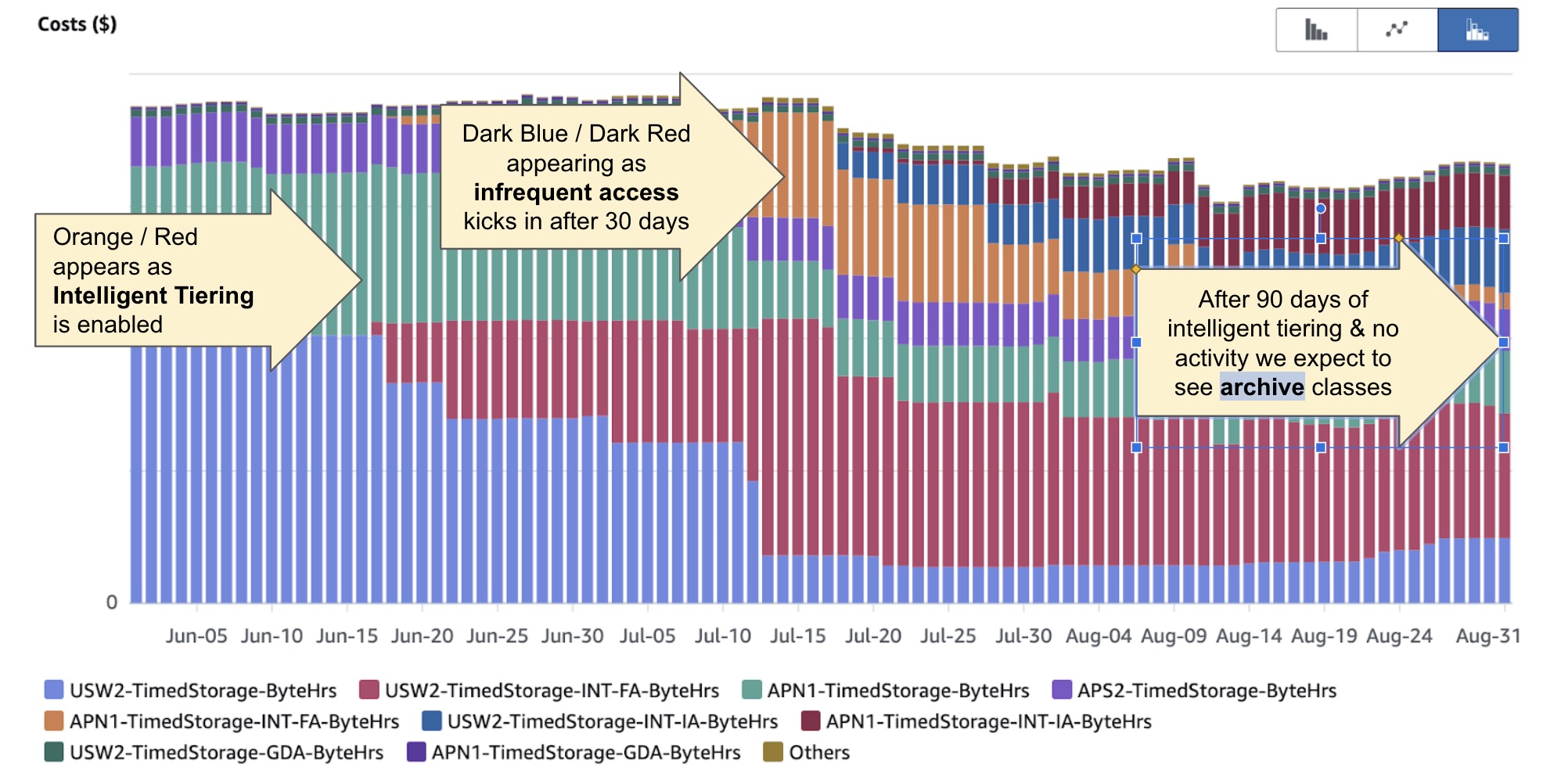
Conclusion
It is interesting to consider alternatives to solving cloud storage with AWS S3 such as those shared by DHH, but for most businesses that is impractical due to the effort and expertise required. It’s also typical for growing businesses that usage requirements can be hard to forecast and the value proposition of the cloud means the utilisation pay-off (only pay for what you use) outweighs the unit-pricing difference. But, data storage management and oversight does require ongoing attention to ensure cost is controlled and other requirements like security and performance are met.